
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
In digital content protection, the “analog hole” represents a unique and persistent challenge. Get insights into how EchoMark is pioneering trusted, hassle-free data sharing, and understand how far we’ve come and what we have learned about AI along the way.

In digital content protection, the “analog hole” represents a unique and persistent challenge. As a career ML/AI researcher, I've been part of the groundbreaking efforts at EchoMark to not only address, but effectively plug this hole, transforming traditional data loss prevention (DLP) with secure, AI-powered solutions. Over the last year and a half at EchoMark, I’ve helped establish some of the core AI technologies. Today, I'm excited to share insights into how EchoMark is pioneering trusted, hassle-free data sharing – explaining how far we’ve come and what we have learned about AI along the way.
The analog hole manifests when digital content, despite being safeguarded by various digital rights management (DRM) techniques, gets transformed back into an analog format—think printed documents or screen captures—only to be digitized again. This process strips away many of the original digital protections and degrades quality, making the leak harder to trace. A classic example of this is the Jack Teixeira classified document case, where a photograph of a printed document circumvented military digital safeguards.
EchoMark’s vision is to facilitate the seamless and trustworthy communication of data. To do this, we’ve developed EchoMark Pixel™ as a solution designed to secure data even when it passes through the analog hole. It does this by uniquely watermarking content to each recipient so that in the event it ever leaked, one can quickly identify the source of the leak. EchoMark Pixel™ doesn't just add watermarks like the old school “DRAFT” that fades into the background; it subtly modifies the document's layout—adjusting spacing and positioning of text—to embed a unique, resilient watermark. While many leaks are digital copies of the content that contain metadata, digital signatures, and other key facets that can aid in an investigation, leaks are starting to look more like this – a picture of the leaked sensitive information.

EchoMark provides products to cover such an analog hole: where the leaked content is derived from a rendered version of the original content. For example, one might take a screenshot of a document, take a picture of a printout from a camera phone, or even take a picture of a computer screen with a mobile device camera.
EchoMark PixelTM is a personalized watermark that survives rendering, distortion, and limited amounts of tampering. The analog hole creates unique challenges that motivate the design of the watermark:
When a watermarked document is leaked, EchoMark leverages advanced computer vision techniques to trace the source of the leak, despite the watermark being difficult for an untrained human eye to detect. This process involves a sophisticated matching problem, identifying the unique spatial relationships encoded within the watermark and matching them to our database of distributed documents.
Unlike the “additive” watermarks that many readers have seen in photographs, EchoMark PixelTM works by adjusting the content itself, namely, the spacing and location of text in a document. The watermarks are designed to be imperceptible and unobtrusive as to preserve the readability and professionalism of the original content.
But, logically questions arise: If it is so hard for a human to pick up these movements, how does a computer do it reliably? Moreover, how can a computer do this with a poor quality image?
Buckle up. This is where it gets technical…
TL;DR – Our approach focuses on the spatial relationships within the document, making minor, almost imperceptible adjustments to the layout. This method ensures that each document carries a unique signature without compromising the document's readability or original intent.
I’m a career ML/AI researcher who spends a lot of time thinking about noise and uncertainty in data. Helping to design the solution here was one of the most interesting problems I’ve worked on in my career. At its heart, watermark identification is a matching problem:
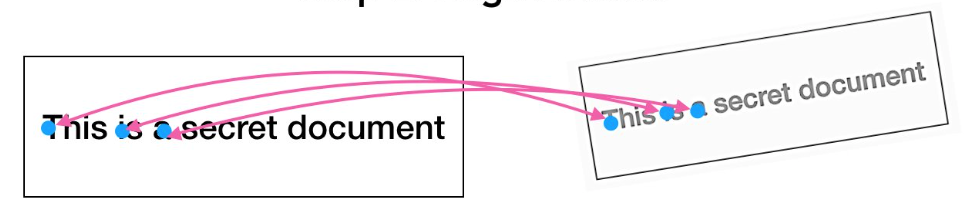
We need to match corresponding pieces of a leaked image of a document to a grounded “source of truth” marked document. Here’s the challenge…every marked copy is VERY similar. They have the same content but there are only minor movements between the letters and words.

How do we disambiguate matches? The signal in this problem is in the spatial relationships between the corresponding marks. We illustrate this with a graphic below. Let’s measure the distance between the word “This” and all other words. We see that the two marked copies have a unique distance profile – some words are further apart and some are closer.
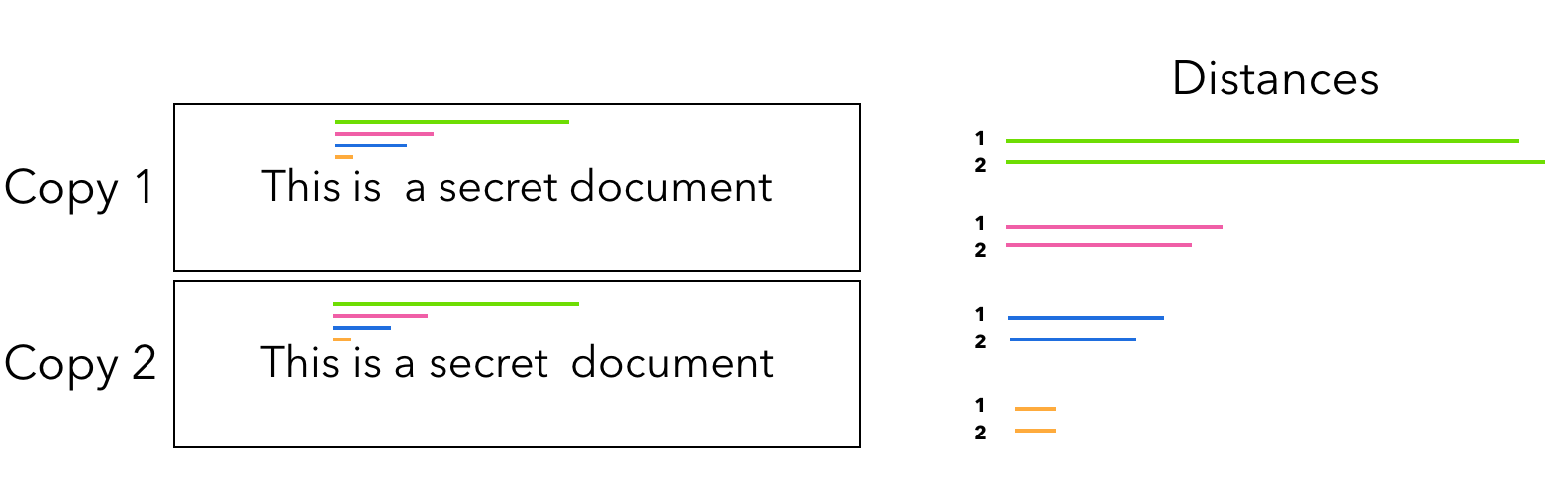
Since these distances are relative to each other, they get transformed in predictable ways when a document is rendered by most standard systems. We assume that the leaked image is a linear “projective” transformation of one of the marked copies. This is an old idea from computer graphics where 3D scenes are projected on 2D renderings consistently. Given a leaked image, we have to find which of the copies is most consistent with a linear projective transformation of it. For example, a proper projective transformation cannot selectively reduce the space between two words in the middle of the line while expanding the others.

While solutions to identifying projective transformations from corresponding pixels are well understood in the academic literature – often called a homography calculation. EchoMark faces a uniquely noisy version of this problem. Here’s an example of a leaked artifact and the corresponding marked copy.

Low quality artifacts like the one above lead to some issues. The input to most homography solvers is a “correspondence”, or pairs of pixels in two images that refer to the same semantic point. When the artifact quality is low we get both false positive and false negative correspondences. Most off-the-shelf solvers for homographies are highly sensitive to such correspondence errors (such as OpenCV’s).
Under the hood of EchoMark PixelTM, is a novel and highly robust solver for homographies aimed at document matching. Here are some of the key highlights:
The effectiveness of EchoMark Pixel™ in our internal testing has been nothing short of remarkable. We've been able to solve homography calculations with up-to 85% error in correspondences (plainly speaking, we accurately match documents with up to 85% error in correspondences), showcasing the potential to revolutionize secure data sharing in an era where digital and analog continuously intersect.
We invite you to experience the power of EchoMark Pixel™ firsthand and join us in redefining the standards of data privacy and security. We're plugging the analog hole and paving the way for secure, trusted, and traceable data sharing for enterprises across the nation. Try it yourself for free, today.



